Project description
Brief of the project
Reuse of learnt knowledge is of critical importance in the majority of knowledge-intensive application areas, particularly because the operating context can be expected to vary from training to deployment. In machine learning this is most commonly studied in relation to variations in class and cost skew in classification. While this is evidently useful in many practical situations, there is a clear and pressing need to generalise the notion of operating context beyond the narrow framework of skew-sensitive classification. This project aims to address the challenge of redesigning the entire data-to-knowledge (D2K) pipeline in order to take account of a significantly generalised notion of operating context.
We will develop an innovative and principled approach to knowledge reuse which will allow a range of known machine learning and data mining techniques to deal with common contextual changes, including:
- changes in data representation;
- the availability of new background knowledge;
- predictions required at a different aggregation level; and
- models to be applied to a different subgroup or distribution.
The approach is based around the new notion of model reframing, which can be applied to inputs (features), outputs (predictions) or parts of models (patterns), in this way generalising, integrating and broadening the more traditional and diverse notions of model adjustment in machine learning and data mining.
The ultimate goal of the project is to provide a much better understanding of the issues involved in the generation and deployment of a model for different contexts, as well as the development of tools which ease the extraction, reuse, exchange and adaptation of knowledge for a wide spectrum of operating contexts. The project will focus on three complex domain areas: geographical applications with spatio-temporal data, smart use of energy (resource production and consumption), and human genomics (genotype-phenotype relation analysis). These three demanding domains will ground the project by means of challenge problems and allow us to experimentally validate our methodologies, tools and algorithms.
Context, objectives and expected results
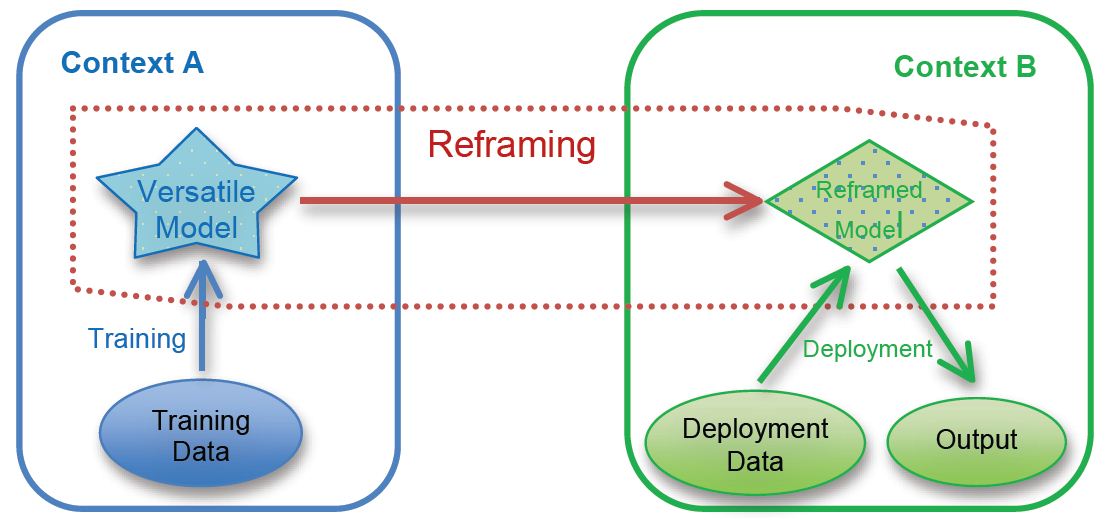
The key notion in machine learning and data mining is the concept of a model, which represents new descriptive or predictive knowledge learned from data. Models are obtained in training conditions and applied in deployment conditions; importantly, these conditions very often differ in one or more crucial aspects. For instance, a model predicting sales in Strasbourg for the following week may fail in Bristol for next Wednesday. The operating context has changed in terms of location as well as resolution. Even if the original model gave good results for the original context, the only solution seems to be retraining a new model for the new context. However, this is often not possible or feasible in economic terms. In fact, even in the cases where it is possible, this may not give good results. For instance, in a recent project with the leading retail company in Spain, the VAL partner found that even if the operating context was set at a daily prediction, better results were obtained if the model was trained on a weekly resolution and then reframed back to predict daily sales by means of disaggregation from weeks to days. This evolution of context, from training to deployment but also from earlier to later deployment, is very common in the consortium’s broad experience with practical D2K projects (See Fig. 1 for a graphical illustration).
As recalled in the next section, the use of ROC analysis to deal with context change has had considerable success, but it is also limited to operating conditions regarding a binary target variable: no equally powerful techniques exist for real-valued targets, for operating conditions on input variables, for operating conditions regarding scale and resolution rather than distribution, etc. It is not yet a general methodology to deal with context change, but it provides an excellent germination point. In this project we investigate the generalisation of operating condition into a much more general notion of operating context as a key element in the process from data to knowledge (D2K) and in the deployment of that knowledge. An operating context will be defined as any set or distribution of conditions, parameters or constraints describing a situation where a model is trained or can be deployed. We will investigate context changes which are common and important in current and future application domains, such as changes in the granularity and reliability that inputs and outputs are given or required, changes in error tolerance standards, changes in data distributions, changes in the availability and cost of the input and output data, changes in the ranges, multiplicities or values features can take or can be negotiated, among others.
In order to operationalise this powerful and dynamic concept of operating context we have introduced the notion of model reframing as the process of adapting an existing model to the new operating context by the proper transformation of inputs, outputs and patterns. The overall objective of this project is, then, the development of generic techniques, methodologies and paradigms for extracting and reusing knowledge (in the form of models, features, rules, ranking information or probabilities) which can be reframed across different operating contexts. As a result, problems such as the example above will be handled as follows: (i) the changes in operating context, such as location and resolution, are identified and formalised; (ii) a more flexible and generic data representation is then used, where inputs and outputs are defined as elements in a hierarchy rather than as single numerical or nominal attributes; (iii) models are built as more versatile and generic entities, working with different locations and resolutions, taking different granularities for inputs and outputs, and producing additional information such as distributions, rankings, reliabilities, etc.; (iv) these models are adapted and integrated through the use of proper reframing operators (aggregation and disaggregation techniques in this particular case); and (v) more sophisticated and powerful performance metrics, evaluating the quality of knowledge in a wide range of operating contexts are used to assess at which resolutions and locations the model is optimal and which learning resolution (e.g. days or weeks) can make the model more flexible and powerful for reframing and deployment in other operating contexts.
State of the art and expected progress beyond state of the art
The ultimate goal of the D2K process is to obtain knowledge that can be used to solve data-driven problems in a variety of situations. Much research in machine learning and data mining has been devoted to coping with an ever-growing variety of data and models, from kernel methods addressing high-dimensional data to relational methods tackling highly structured data. In practice this means that given a problem, the best possible selection of available techniques is performed, where this choice is based on how well the model performs on the problem at hand. This commonly results in overfitting to the training context, which restricts model applicability whenever the training conditions change. As a result, models must be discarded and retrained repeatedly, which is not cost-effective.
Machine learning has addressed this problem in limited ways. One common way is the use or assumption of a more general data distribution: either theoretically or empirically, e.g., by the use of additional data covering a broader space (semi-supervised learning). However, a general model is not necessarily good for adjusting well to particular situations again. One reason for this is that a general model may not be ready for using information about each new specific context where it is meant to be applied. Crucially, in many situations we do have information about the new context. An advanced approach to model exploitation would use this information to adjust the deployment of a model, e.g., by modifying the decision rules, resulting in a quantum leap in terms of reusability and flexibility. The current state of the art in machine learning, however, only allows for an appropriate use of this information in a quite restricted set of scenarios, basically cost functions for the output attribute and distribution changes for the input and output attributes, as we briefly review now.
Context change in machine learning has been studied primarily through operating conditions defined by cost/utility matrices and class imbalances. For instance, if a classification model was trained for a uniform class distribution, there are techniques to adapt the model to other class distributions or skews. The tools for doing this in a classification task are now commonplace and are mainly based on ROC analysis [F10] or cost-sensitive learning [LS10]. These tools allow the knowledge engineer to (i) determine optimal operating points under the given operating condition; (ii) identify regions of optimality where one model dominates others; (iii) link the model scores to actual operating conditions in the domain through calibration; and (iv) construct optimal hybrid models that combine the dominance regions of an ensemble. To achieve all this, the notion of a model was extended from a crisp classifier to one outputting ranks or scores. Furthermore, many evaluation metrics and loss functions can be understood as an aggregation of costs in a range of operating conditions [HFF11]. The tools and theory around these concepts have significantly helped to build and apply models with a much better adjustment to costs, utilities and class frequencies.
Transfer learning [PY10] is a closely related and diverse area where emphasis is put on a change of distribution and also on whether (or in which proportions) examples are labelled between the source learning task and the `target’ learning task. In addition, the notion of feature-representation transfer has also been analysed, but models are not conceived to be more versatile or general a priori. Similarly, model or theory revision delays the problem to deployment time and undertakes a change of the model, while what we want (and lack) is that the original model need not be dismissed and substituted by the new one, but just deployed in the appropriate way for the new situation. In other words, we do not want to build a set of models for a range of operating contexts or a very general, but inflexible, model, but rather a single versatile model which can be properly deployed in a range of operating contexts using all the available information about each context. Any advance in this regard, as the objectives of this project propose, constitutes an important innovation over the current state of the art (see also Figure 1).
Not every kind of information about the training and deployment contexts is sufficiently formal or operational to be integrated into a more advanced and flexible model deployment scenario. While we do not discard the application of more complex and sophisticated kinds of context changes in the future, given the size of the consortium and the novelty of some of the key ideas the project relies on, we consider three strands which are better suited to develop a general notion of operating contexts working as ‘parameters’ for model reframing.
Changing inputs and outputs: One of these strands is given by the change in number, character and nature of the input and output attributes. Many systems can deal with missing data or with unreliable data for some examples, or attributes for which new values appear during deployment time, but are not able to treat overall contextual information about these issues. Similarly, we lack tools when outputs can change; e.g., we have new classes, or a classification problem turns into a regression problem, or vice versa. In some occasions, the problem may need to be inverted, i.e., the model can be used to get the inputs from the outputs. This has been explored under the notion of negotiable features [BFHR11] but there is an almost unlimited potential for further progress in terms of reframing, including the extension of performance evaluation with these changing problem arrangements.
Relational data and background knowledge: A powerful and well-grounded area where information about context can be effectively treated is when context is given by changes in secondary relations (linked to the main relations by many-to-one relationships), in new features or in background knowledge. The approach taken by Inductive Logic Programming and relational data mining [D10] is perhaps the most powerful and flexible. The use of ‘quantiles’ was introduced in [LLB09,BL11] in order to calibrate continuous attributes of objects having a many-to-one relationship to the main individual in an urban blocks classification problem [PSLBP11]. The logical setting also provides versatile mechanisms to deal with incomplete knowledge and missing data through nonmonotonic reasoning and abduction [FK00], where a model can behave differently when reframed to the new context with these techniques. In the relational setting, background knowledge can be effectively changed with immediate effect on how a model operates, clearly suggesting how reframing could be done. Other kinds of background knowledge, can be used, for instance through a clustering method [FGW10].
Hierarchical and multidimensional representation: Hierarchical data is one of the areas where the application of a model to different contexts is often required, and the state of the art is still very limited. Hierarchies are usually exploited in different ways depending on the domain. Models which are generated from one dimension and level cannot be used for other dimensions or levels. These problems appear in areas such as granular computing [LYZ02], hierarchical modelling, multidimensional databases, subgroup discovery, quantisation and discretisation. In general, some tools may be useful for extending models to other parts of a hierarchy, such as quantification [F08,BFHR10], transduction, calibration, co-learning, etc. For instance, quantification is a relatively new machine learning task that can be, in principle, generalised to involve the aggregation of heterogeneous sources of information (hierarchical or not) and very different kinds of models. Existing techniques for the integration of data mining and multidimensional data warehousing (e.g. prediction cubes [CCLR05]) do not consider any of these techniques, and are not based on more versatile models working across the hierarchy, but on partial models which are put together when navigating through the data cubes.
As we have seen, contexts are not only given by changes of costs or distributions. We lack then a generic set of techniques which consider other common contexts from which we can render any available information effective. For this we also lack the definition of more versatile models and flexible reframing operators which can use this information. Much progress is possible in any of the strands above in order to attain a much better model exploitation. A more fundamental advancement we expect is given by a better understanding of the essence of a cost-effective D2K process; how models must be constructed (in terms of the information they need to collect and produce) in order to allow for a more powerful and efficient model exploitation in different contexts.
Scientific description of the project
The comprehensive way in which context change is embraced and exploited by model reframing is the main innovation of the REFRAME project and will naturally develop and bring together the most suitable of the research strands reviewed in the previous section. The idea of generalising the context and not only the data is the key to solving some of the most challenging problems the discipline has been facing in recent years. Since specific models are difficult to reuse and adapt to other contexts, the life of machine learning models has often been very short. By constructing more versatile models in the training context we will be able to adapt them through reframing to different (current and future) deployment contexts (Figure 1).
Figure 1. Operating contexts, models and reframing. The model on the left is intentionally more versatile than strictly necessary for context A, in order to ease its reframing to other contexts, such as context B.
These new and generalised concepts require a re-appraisal of the whole process from data to knowledge and deployment. The project will therefore address the following five key areas.
- A1. Operating contexts
- We will develop a proper formalisation of operating contexts, in terms of how they can be quantified and represented, how we can define sets (and probability distributions) over operating contexts, and analysing their properties. Through three application domains (see below) we will recognise a variety of operating contexts ensuring that our notion of operating context is most general.
- A2. Generic data representation
- Data needs to be represented in such a way that it becomes much easier to tailor when context changes. This involves generalisation and mapping operators which convert a particular problem in a specific operating context into a more general, parametrisable, problem, to allow feature reframing.
- A3. Versatile model extraction
- We need methods to build models which are more flexible and robust for different operating contexts in the way they process inputs and outputs with varying degrees of granularity and reliability, and in different formats. This relies on a generalisation of the inputs but also on more informative outputs.
- A4. Model and prediction integration
- This requires the development of techniques for aggregating, disaggregating and combining models, rules and predictions. This will rely on output reframing procedures which will be defined from new or existing techniques such as quantification, calibration, fusion, co-learning, etc.
- A5. Performance assessment
- A generalised notion of model dominance, new performance metrics and graphical representations need to be developed for assessing loss or utility in a more general notion of context, evaluating predictions at different levels and scales, spanning over several tasks and different periods of time.
These five areas describe where the project takes effect. Partial approaches to any of these areas alone cannot give satisfactory and broad-spectrum solutions. We hence address these areas in the project through the following technical pathways.
Technical pathways
A suitably generalised notion of operating context requires that the information about the context can be properly formalised and parametrised. Consequently, it is natural to base our proposal on technical pathways (sets of techniques and frameworks) where these notions are realistic, precise, broad and sound. The technological methodology of the REFRAME project is then built on the following three main technical pathways:
One key insight underlying the whole project is that the benefits of ROC analysis can be extended well beyond the restricted view of operating condition as a class distribution or a cost proportion. The notions of dominance, operating point, threshold choice, probability calibration, and aggregated performance metrics such as AUC can be generalised to a much wider range of operating contexts. The generalisation to non-binary and real-valued target variables, input variables of various types, and feature ensembles and hierarchies provide very concrete starting points for the workplan and give a feasible basis to the ambitious overall project goals.
The second pathway relies on multi-relational data mining which not only can represent many specific operating contexts, but also focuses on data involving multiple entities and one-to-many relationships, such as customers and their purchases. So a change of distribution of the purchases, i.e. of their cardinalities, is a change of operating context specific to relational data mining. We will investigate representations and the associated learning mechanisms to manage these kinds of changes, such as nested one-to-many relationships, previously unobserved classes, etc. In addition, change in background knowledge is also a flexible and versatile way of representing context changes, and one that can incorporate assumptions about missing data by means of abductive inference.
Finally, the notion of multidimensional operating context is a novel, powerful and broad (but precise) instance of how an operating condition can be generalised. Given a multidimensional arrangement of the data (possibly but not necessarily in the form of a multidimensional data warehouse), where the problem attributes are represented by hierarchical dimensions, a multidimensional operating context is a collection of probability distributions for the input and output features of a given problem at a given granularity level. This notion will function as another early proof of principle from the outset of the project and as a viable way of integrating the developed technologies into data analysis tools which combine data warehousing and data mining.
Application domains
In addition to a clear set of technical pathways, we build on real-world domains to guide and constrain the generalisation of operating context. This sets up a bottom-up scientific methodology, from real problems to effective solutions. The domains must cover a heterogeneous set of possibilities, in order to apply momentum and validate the contributions of this project. We will focus on three core application domains: geographical data, smart electricity meter data, and Human Genomics
References
[BFHR10] A. Bella, C. Ferri, J. Hernández-Orallo, M.J. Ramírez-Quintana: "Quantification via Probability Estimators", IEEE International Conference on Data Mining 2010, Sydney, IEEE Computer Society, pages 737-742, 2010.
[BFHR11] A. Bella, C. Ferri, J. Hernández-Orallo, M.J. Ramírez-Quintana: "Using negotiable features for prescription problems", Computing, Springer, vol 91(2), pp. 135-168, 2011.
[BL11] A. Braud, N. Lachiche: “Propositionaliser des attributs numériques sans les discrétiser, ni les agréger”. Extraction et Gestion des Connaissances (EGC), pp. 437--442, Cépaduès-Éditions, Revue des Nouvelles Technologies de l'Information, Vol. E.20, 2011.
[CCLR05] B.C. Chen, L. Chen, Y. Lin, R. Ramakrishnan: “Prediction Cubes”, Proc. of the 31st International Conference on Very Large Data Bases, 982--993, 2005.
[F10] P. Flach. “ROC Analysis”. Encyclopedia of Machine Learning, pp. 869-875, 2010.
[FD01] P. Flach, S. Dzeroski: “Editorial: Inductive Logic Programming is Coming of Age”. Machine Learning, 43 (3). 2001.
[F08] G. Forman: “Quantifying counts and costs via classification”. Data Min. Knowl. Discov. 17(2): 164-206, 2008.
[FGW10] G. Forestier, P. Gançarski, C. Wemmert: “Collaborative clustering with background knowledge”, Data & Knowledge Engineering, pp. 211--228, Vol. 69, Num. 2, 2010.
[FH01] E. Frank, M. Hall: “A Simple Approach to Ordinal Classification”. ECML 2001: 145-156.
[FK00] P. Flach, A. Kakas: “Abduction and Induction: Essays on their relation and integration”, Springer, 2000.
[HFF11] J. Hernández-Orallo, P. Flach, C. Ferri: “Threshold Choice Methods: the Missing Link” Arxiv preprint arXiv:1112.2640, 2011.
[HNF07] S. Hoche, A. Nuernberger, P. Flach: “Network Analysis in Natural Sciences and Engineering”. AI Communications, 20(4). December 2007.
[HRF04] J. Hernández Orallo, M.J. Ramírez Quintana, C. Ferri Ramírez: “Introducción a la Minería de Datos” Pearson – Prentice Hall, 2004.
[L10] L. De Raedt: “Inductive Logic Programming”. Encyclopedia of Machine Learning. pp. 529-537, 2010.
[LLB09] J. Lesbegueries, N. Lachiche, A. Braud: “A propositionalisation that preserves more continuous attribute domains”, Poster session of the 19th International Conference on Inductive Logic Programming. 2009.
[LS10] C. X. Ling, V. S. Sheng: “Cost-Sensitive Learning”. Encyclopedia of Machine Learning, pp. 231-235, 2010.
[LYZ02] T.Y. Lin, Y. Yao, L.A. Zadeh (eds.): “Data mining, rough sets, and granular computing”, Springer, 2002.
[PLC10] O. Pastor, A.M. Levin, J.C. Casamayor, M. Celma; L.E. Eraso, M.J. Villanueva, M. Perez-Alonso: “Enforcing conceptual modelling to improve the understanding of human genome” Research Challenges in Information Science (RCIS), pp. 85-92, IEEE 2010.
[PSLBP11] A. Puissant, G. Skupinski, N. Lachiche, A. Braud, J. Perret: “Classification et évolution des tissus urbains à partir de données vectorielles”. Revue internationale de géomatique, 2011.
[PY10] S.J. Pan, Q. Yang: “A survey on transfer learning”, IEEE Transactions on Knowledge and Data Engineering, 22, 10, pp. 1345-1359, 2010.
Glossary
The Glossary is aimed at newcomers and people with questions about the terminology and relation of reframing with other concepts such as ROC analysis, transfer learning, dataset shift, theory revision, calibration, etc.